发表在《自然》杂志上的一篇论文提出了一个评估大型语言模型(llm)如何回答医学问题的基准。这项来自谷歌研究的研究还介绍了医学领域专门的法学硕士Med-PaLM。然而,作者指出,在llm能够用于临床应用之前,必须克服许多限制。
人工智能(AI)模型在医学领域具有潜在的用途,包括知识检索和临床决策支持。然而,例如,现有模型可能产生令人信服的医疗错误信息,或包含可能加剧健康差距的偏见。因此,需要对他们的临床知识进行评估。然而,这些评估通常依赖于有限基准的自动评估,例如个人医学测试的分数,这可能无法转化为现实世界的可靠性或价值。
为了评估法学硕士编码临床知识的能力,Karan Singhal、Shekoofeh Azizi、Tao Tu、Alan Karthikesalingam、Vivek Natarajan和同事们考虑了这些模型回答医学问题的能力。
作者提出了一个名为MultiMedQA的基准,它结合了六个现有的问题回答数据集,涵盖专业医学,研究和消费者查询,以及HealthSearchQA,一个新的数据集,包含3173个经常在线搜索的医学问题。
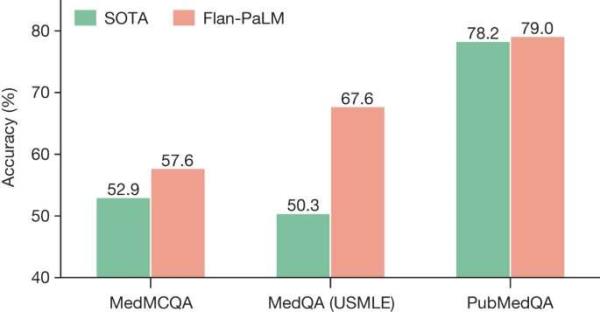
然后,作者评估了PaLM(一个5400亿参数的LLM)及其变体Flan-PaLM的性能。他们发现,Flan-PaLM在几个数据集上取得了最先进的性能。在包含美国医疗许可考试风格问题的MedQA数据集上,FLAN-PaLM比以前最先进的法学硕士高出17%以上。然而,虽然FLAN-PaLM在多项选择题上表现良好,但人类的评估显示,它在回答消费者医疗问题时的长格式答案存在差距。
为了解决这个问题,作者使用了一种称为指令提示调整的技术来进一步使Flan-PaLM适应医学领域。指令提示调优被引入作为一种有效的方法来调整通才法学硕士到新的专业领域。
他们的最终模型Med-PaLM在试点评估中表现令人鼓舞。例如,一组临床医生认为,只有61.9%的Flan-PaLM长格式答案与科学共识一致,而Med-PaLM的答案为92.6%,与临床医生生成的答案(92.9%)相当。同样,29.7%的Flan-PaLM答案被评为可能导致有害结果,而Med-PaLM的这一比例为5.8%,与临床医生生成的答案(6.5%)相当。
作者指出,虽然他们的结果很有希望,但进一步的评估是必要的。
更多信息:Karan Singhal等人,大型语言模型编码临床知识,Nature(2023)。DOI: 10.1038/s41586-023-06291-2期刊信息:Nature
自然出版集团提供引用:对AI回答医学问题的能力进行基准测试(2023年,7月14日)检索自https://medicalxpress.com/news/2023-07-benchmarking-ai-ability-medical.html本文档 作品受版权保护。除为私人学习或研究目的而进行的任何公平交易外,未经书面许可,不得转载任何部分。的有限公司 内容仅供参考之用。
本文来自作者[啊爹]投稿,不代表文学号立场,如若转载,请注明出处:https://www.8ucq.com/wenxuehao/1933.html

评论列表(4条)
我是文学号的签约作者“啊爹”!
希望本篇文章《测试人工智能回答医学问题的能力》能对你有所帮助!
本站[文学号]内容主要涵盖:文学号, 名著深析, 创作秘笈, 经典文脉, 诗词鉴赏, 作家故事, 每日文萃, 写作指南, 文本细读, 文学灯塔, 经典重释
本文概览:˂pclass="8c20-a027-fc95-59d8 description"˃˂pclass="a027-fc95-59d8-8edd description"˃发表在《自然》杂志上的一...